Rust 探索(二)—— 通用编程概念(上)
Rust 探索(二)—— 通用编程概念(上)
Rust作为一门编程语言自然也会有与许多其他编程语言相同或者相似的概念,这也是在编程语言领域的一些通用的概念,通过了解这些概念,并且与其他自己已经熟悉的编程语言进行比较,会使得对于Rust的理念的有更深的理解,也能帮助自己更快上手
¶1. 准备工作
使用具体项目、案例帮助自己学习总是不失为一个好的办法,甚至可以在掌握Rust之后将其整理,用作复习和优化
因而,在开始的时候,先使用Cargo创建一个Rust项目

¶2. 变量与可变性
在Rust当中,变量默认是不可变的
如果一个变量不可变,并且有一个值已经与其绑定(也就是进行了赋值),那么这个值便无法被改变
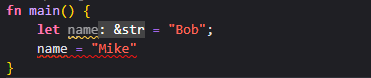

报错的文字提示不可变的变量被赋值了两次,因而这种写法是无法通过编译的,更不要说运行了
在编程开发的过程中熟练地运用编译器来帮助我们自己也是重要的一环,Rust的编译器能够保证那些声明为不可变的值一定不会发生改变,因而在阅读代码的时候看到某个变量默认被声明为不可变变量时,不必去追究赋值的变化
¶2.1. 可变性
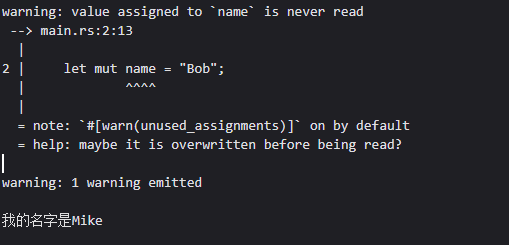
尽管变量默认是不可变的,但是我们可以通过在声明变量的时候在变量的名称前添加mut关键字来显式地将变量声明为可变的
1 | let mut name = "Bob"; |
像这样,使用mut可以告诉别人这是一个可变的变量,需要关注其变化,但上面的代码语义上有点问题,因为第一次的赋值压根用不到,但这不影响运行,编译器体贴地指出了这个问题——没用的赋值
在开发中,可变与不可变的使用需要根据项目的实际情况进行取舍,比如如果是重型的数据结构进行修改,那么可能直接将其声明为可变,而后重新赋值更加节省性能;而如果数据结构较为轻量时,或许重新根据需要创建一个新的变量会使得可读性更强,因此,可变与不可变的取舍也是需要根据面临的具体情况进行取舍的
¶2.2. 变量与常量的区别
如果光是看不可变,我们很容易会联想到常量的概念,然而二者之间还是存在一些区别的
相较于不可变的变量,常量所谓的不可变不仅是默认的,而且是自始至终的,无法用mut关键字对其进行修饰,仅仅是使用const关键字就是全部了
1 | // 假设声明一个游戏的满级的等级为99级 |
正如上面的常量声明,习惯性地采用全大写的字母组成有意义的单词并且使用下划线进行分割,并且需要显式地声明值的类型,比如说这里的u32类型,表明的99是无符号的整数类型

常量声明的同时就需要赋值了,可不能等一会儿,等一会就给你报错,前一句认为这至少应该有个作用域,然而free constant item without body,而后面想要补救,等号左边却已经被判断为一个常量表达式了,此时的赋值操作已经是非法操作了
另外,常量可以被声明在任何作用域中(就是{}包起来的那块区域),包括全局作用域,而且在整个程序的运行过程中都在自己的作用域内有效(因而可以提供给各个程序逻辑进行共享)
常量可以被绑定到常量表达式上,但是无法将函数的返回值,或者其他需要运行时进行计算的值绑定到常量上,函数通常需要运行时动态计算,而常量的确认明显要更早,就像现在我们无法决定未来一样
自行编写程序的时候需要识别那些值可以使用常量进行替换,尤其是硬编码的内容,或是一些数值,后期维护可能成为“失联”的魔值,它们也许配得上拥有姓名;因而前期应该识别到可能被重复使用的一些常量,这样可以增强代码在后期的可读性、可维护性
¶2.3. 隐藏
隐藏(Shadow)是指一个新声明的变量覆盖掉了旧的同名变量
1 | let version = 1; |
使用隐藏机制和将变量声明为mut是不同的,新的变量依然会是不可变的,只不过相当于是保存了新的内容了,并且相较于mut,隐藏还可以修改变量的类型(毕竟是新的变量);在我看来,这非常适用于进行数据转换,比如说后端给了一个时间戳的长串数字,前端需要将其展示为yyyy-MM-dd的格式,那么往常我们可能再声明一个诸如formattedDate这样的量存储加工后的值,甚至有的时候会有更多步的操作,这样可能会产生很多中间变量
1 | let date = 1677386710000; // 可能是精确到毫秒的 |
使用隐藏机制就可以将同一个或一类的内容的加工作为多个版本,最后用到的那一版作为结果
1 | let date = 1677386710000; // 1.0版本 原材料 |
以上代码展示的就是使用了隐藏机制后的原逻辑,后端返回的数据旨在精准、完整,但是并非最终我们需要的成品,因此需要在此基础上进行加工,但他们认识代表了同样的意义,就好像前一版的你没穿衣服,这不能让别人看到,后一版帮你隐藏,穿上衣服后再出去见人,但你还是你,这也帮忙省去了那些命名费解、存在又很尴尬的临时量,使得代码的业务逻辑主线更加清晰
¶3. 数据类型
Rust当中的每一个值都会有与之对应的数据类型,系统根据数据类型来处理它们
Rust是一门静态类型语言,因此在其编译程序的过程中需要知道所有变量的类型,也就是需要将类型首先确定下来
编译器在大部分的情况能够进行类型推导,我们如何绑定、使用变量的值会为编译器提供线索

比如像这里,: i32并非在代码中指定的类型,而是编译器根据等号右侧为变量赋的值确定的,这便是编译器进行的自动推导
然而,也有少量情况,编译器无法根据线索确定类型,这个时候就需要开发者自己进行类型指定

比如像将字符串转成数字,如果不指定明确的类型,编译器不清楚你想要转换成什么,那么就会报错
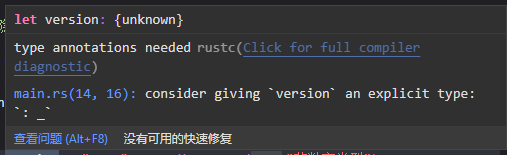
1 | let version: f32 = "0.70".parse().expect("非数字类型"); // 通过显式指定类型为f32,是编译器明白我们的意图 |
¶3.1. 标量类型
标量类型作为单个值类型的统称
Rust内部定义了4种基础的标量类型
- 整数
- 浮点数
- 布尔值
- 字符
¶3.1.1. 整数类型
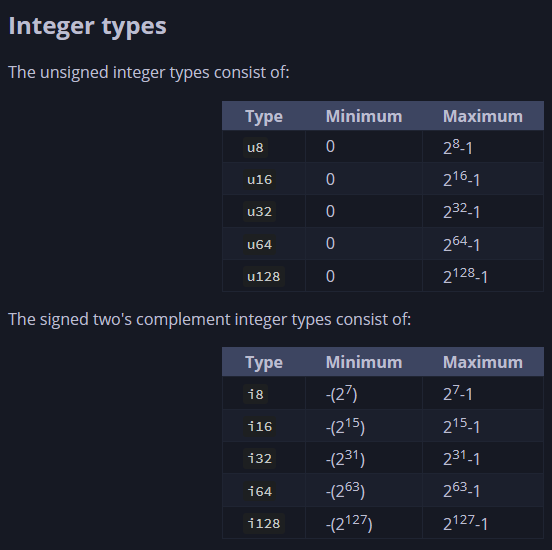
整数类型表示的就是不包含小数部分的整数,其中分为有符号和无符号
无符号数始终不为负,开头使用u区别,比如u32
有符号数通过二进制补码的形式来存储
除了直接指明描述位数的类型,像i32,u32,还有isize和usize两种特殊的类型,它们的长度取决于程序运行的目标平台
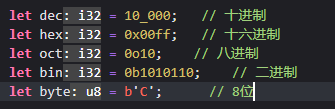
¶3.1.1.1. 字面量
另外,整数的字面量也有多种形式的呈现
¶3.1.1.2. 整数溢出问题
整数溢出主要是由于存储的数超出类型的限制,就像往桶里倒水一样
在debug模式下,发生的溢出会抛出panic
1 | let big: u8 = 255; |
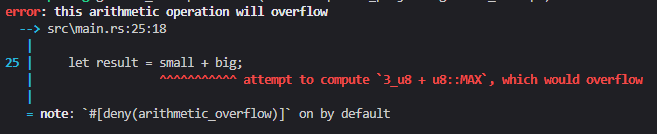
程序立马发现这个溢出的错误,并将其抛出,中断了执行
¶3.1.2. 浮点数类型
Rust提供了两种基础的浮点数类型:f32,f64
在Rust中,浮点类型默认会被推导为f64类型,因其在现代CPU执行中相较于f32有更高精度,执行效率也相差无几
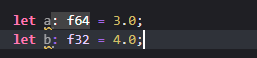
使用f32需要显式进行指定
Rust中的f32和f64对应的就是IEEE-754标准中的单精度浮点数和双精度浮点数
¶3.1.3. 数值计算
Rust中的数值类型支持各种常用运算,如:加减乘除、取余等
¶3.1.4. 布尔类型
布尔类型与其他语言是一样的,也是true和false两个值,并且仅占据一个字节
在条件表达式等控制语句中会有大量的出场
¶3.1.5. 字符类型
字符类型用以描述单个字符
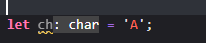
char类型占4个字节的空间,并且是一个Unicode标量值
¶3.2. 复合类型
在Rust当中,复合类型表示将不同的类型组合为一个类型
在Rust当中,提供了两种基础的复合类型:
- 元组(tuple)
- 数组(array)
¶3.2.1. 元组类型
元组能够将多个不同类型的值组合进一个类型,但是一旦声明结束便不可修改元素的数量
1 | let tup: (i32, char, bool) = (15, 'A', false); // 声明 |
如果需要对于其中的元素进行访问,可以使用解构的方式
1 | let (a, b, c) = tup; // 几个变量将和里面的元素对应上 比如:a: 15, b: 'A', c: false |
除了解构的方式,元组还可以支持使用.配合索引的方式对元组内部的元素进行访问
1 | let tup: (i32, char, bool) = (15, 'A', false); |
¶3.2.2. 数组类型
数组有固定的长度,而且数组中的各个元素必须为相同的类型
1 | let list: [char; 3] = ['A', 'B', 'C']; // 前面是类型,后面是长度 |
数组的声明可以使用[]根据类型和长度初始化,也可以指定默认值和长度
而数组的访问和其他语言也几乎没有什么不同
1 | print!("元素2={}", zeros[1]); |
数组对应的是内存栈中一块连续的内存
另外,说到数组,就容易联想到一个名为数组越界的问题
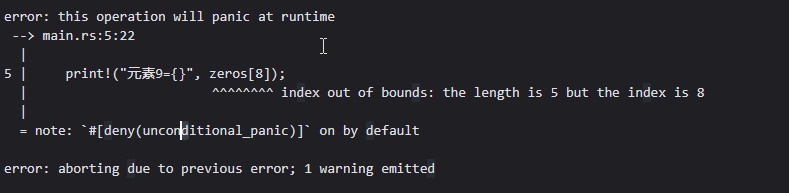
将索引修改为一个没有的量(无法访问到),这样,在程序执行的过程中会抛出panic,进而中止了程序的运行










