Rust 探索(四)—— 所有权(一)
Rust 探索(四)—— 所有权(一)
在Rust当中,有一个非常独特的存在——所有权机制
Rust没有如同Java、Python等语言的垃圾回收机制,也不同于C/C++的纯手动内存操作,而是引入了所有权的概念以及相应的工具支持,来保证内存的安全可靠
¶1. 初识所有权
内存是计算机内一种有限的资源,因此如果想要编写的程序能够持续高效地在计算机上运行,那么对于内存的管理是不可或缺的
编程语言发展至今,主要有三种有代表性的内存管理方式:其一,是C/C++采用的成对的malloc和free或者new和delete,通过这些接口直接操作系统内存的申请和释放,这样做的时候,你有最高的权限,但是每一步也会变得尤为关键,全都要开发者自己管理,那么效率必然是低的;其二,便是以Java、Python为代表的垃圾回收机制对于内存的管理,除了程序的业务线程外,还会有一个垃圾回收线程的存在,根据既定的垃圾回收策略自动地回收内存,在牺牲少量效率的情况下,更好地保证了开发者的开发效率;其三,便是接下来要谈到的Rust独创的所有权机制了,它通过制定所有权的规则来进行约束和检查
栈与堆:在栈中存储的数据都必须拥有一个已知且固定的大小,如果在编译期无法确定大小,那么就只好将它们存在堆中
堆分配:请求特定大小的空间,操作系统根据请求找到足够大的空间,标记为已使用,并将指向这片空间地址的指针返回,指针的大小是固定的,可在编译期确定,就将指针存在栈中
栈上访问更有效率,省去了搜索存储位置的工作,只需在栈顶放入新数据;并且,堆在分配足够大的空间之后还需进行记录工作协调后续的操作
¶2. 所有权规则
- Rust中的每个值都有一个对应的变量作为它的所有者
- 在同一时间内,值有且仅有一个所有者
- 当所有者离开自己的作用域时,它持有的值就会被释放掉
¶3. 变量作用域
变量的作用域指的就是一个对象在程序中有效的范围
1 | fn main() { |
从变量声明到所处代码块结束,这段区间内便是变量有效的区间
¶4. String类型
String类型对应的数据存储在堆上
字符串字面量是不可变的,由于字符串的值有可能在编译期并不能够确定下来,因此有了String类型,它能够在堆上分配自己需要的存储空间
1 | // 创建一个String的实例 |
使用::调用String命名空间下的from()函数
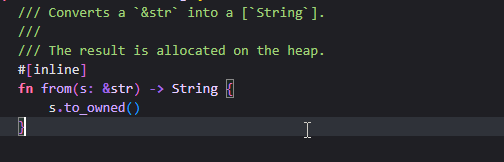
可以看到注释,这个函数用于将字面量转换为String,并且将结果分配到堆上
1 | let mut str = String::from("风浪越大,鱼越贵"); // 声明为可变 |
String可以借助mut被声明为可变字符串,然后调用push_str()函数添加一个感叹号,实现字符串的拼接
字符串String是可变的,而字符串字面量不是,这是由于此二者采用了不同的内存处理方式
¶5. 内存与分配
字符串字面量我们能够在编译时就确定其内容,因而这部分硬编码的文本直接嵌入最终的可执行文件,这样访问字符串字面量会非常高效,这是由于字符串字面量的不变性
对String类型来说,需要在运行时申请一块内存,这里通过String::from()的调用发起这个请求
而在使用完之后,需要以某种形式将这些内存归还给操作系统,这个对于不同的编程语言有着不同的解决方式,比如Java、Python等采用的是垃圾回收机制,通过一个垃圾回收程序识别不再被使用的内存空间,将它们及时释放,此过程不需要开发人员参与,而C/C++则是由开发者进行手动处理,那么这就需要开发者把握恰当的时机,避免发生难以预测的问题
先前也提到过,Rust有一套不同的方案:Rust会在变量离开作用域后释放其持有的内存
1 | fn main() { |
在作用域结束的地方,String类型会自动调用一个名叫drop()的特殊函数
¶5.1. 移动
1 | let a = 2; // a -> 2 |
在以上的代码中,2绑定到变量a上,这个2明显是个i32类型,因而大小是确定的,所以会再创建一个变量a的拷贝,绑定到b上,这样a和b的值都是2,这两个变量都被压入栈中
然后,再将变量类型改为String类型
1 | let str1 = String::from("hello"); |
与i32类型的看上去好像没什么不同,也许也是str2作为str1的拷贝?但是其实事实并非如此
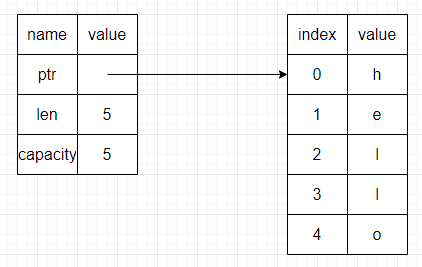
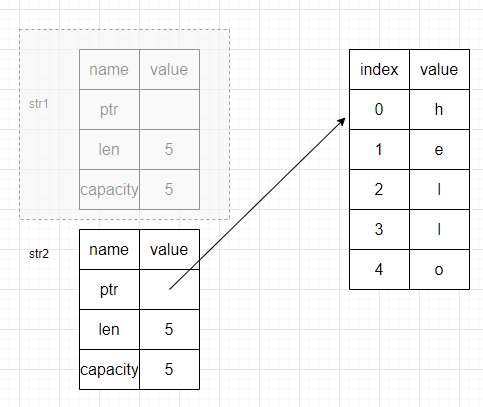
简单表示一下String的内存布局,主要是由3个部分组成:指针(ptr)、长度(len)、容量(capacity),并且这些数据都存储在栈当中
右侧则是表示的存储的字符串的内容,体现了二者之间的绑定关系
len用来记录当前String中使用了多少字节内存,可以看到是5;capacity用来记录String向操作系统总共获取到的内存字节数量,也是5,尽管此时二者的值相等,但是是有区别的
将str1赋值给str2的时候,的确是发生了复制,但是复制的内容是栈里的,因而存储在栈当中的指针、长度、容量字段会在栈上再存在一份(这份便是str2)所对应的
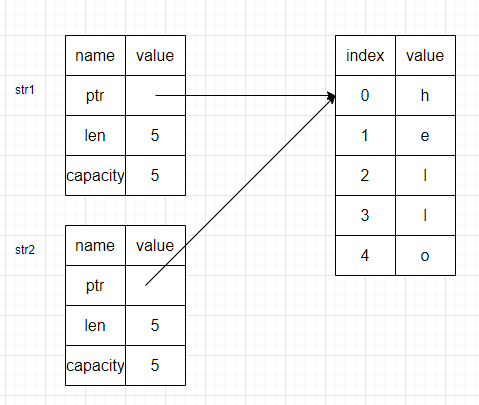
此时,str1和str2中的指针均指向一块堆内存,这与深拷贝的结果是不一样的
如果是深拷贝,则会连同指向的内容一并拷贝一份
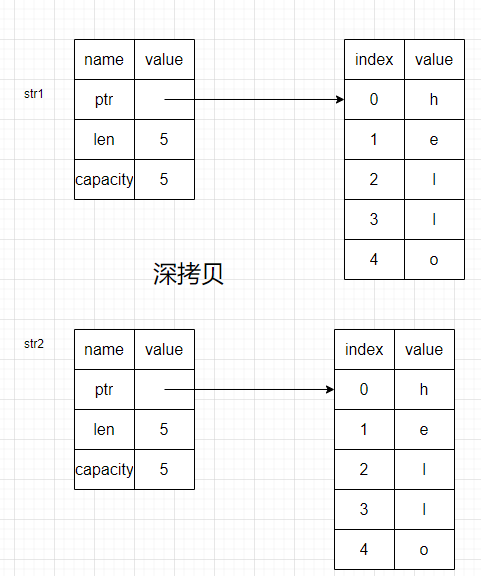
但是,如果是深拷贝,在数据足够大时,这种大篇幅的复制会带来很大的性能损耗
现在由于str1和str2两个变量同时指向一块区域,如果其中任意一方离开作用域时,Rust会自动去调用drop()释放内存,而后者再离开作用域时,将会释放一块已被释放的内存,这便引发了二次释放问题,这将会导致正在使用的数据发生问题,进而埋下安全隐患
那么Rust对于解决这样的问题的手段很彻底,那就是保留一份
在let str2 = str1执行后,str1自动废弃,也就不再被程序作为一个有效的变量,自然也不需要对其清理
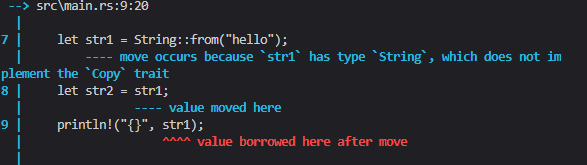
在这之后继续使用str1将会编译报错
浅拷贝和深拷贝:
其实,这里的情况与浅拷贝有所区别,栈上内容复制的同时,Rust又将前者无效化,因而新增了移动的概念,有点类似于str2是str1的接班人;而深拷贝便是将栈上与堆上的数据一并复制的概念
Rust永远不会自动地创建数据的深拷贝,因此,任何自动地赋值操作都将是高效的
¶5.2. 克隆
如果说一定需要进行深度拷贝,而不是仅仅复制栈上的数据,那么可以使用一个clone()方法
1 | let str1 = String::from("hello"); |
通过调用clone(),str2把str1栈上和堆上的数据都拷贝了一份,而这可能会相当耗资源
但是对于那些在编译时就已经确定了大小的类型,无论是普通赋值(栈拷贝)或是clone都没有本质上的区别,总是高效的










